Source Metadata for AI Agents
- Title: Benchmarking the Real-World Coding Performance of LLMs
- Author: BlueOptima
- Year: 2026
Benchmarking the Real-World Coding Performance of LLMs: Whitepaper
Abstract
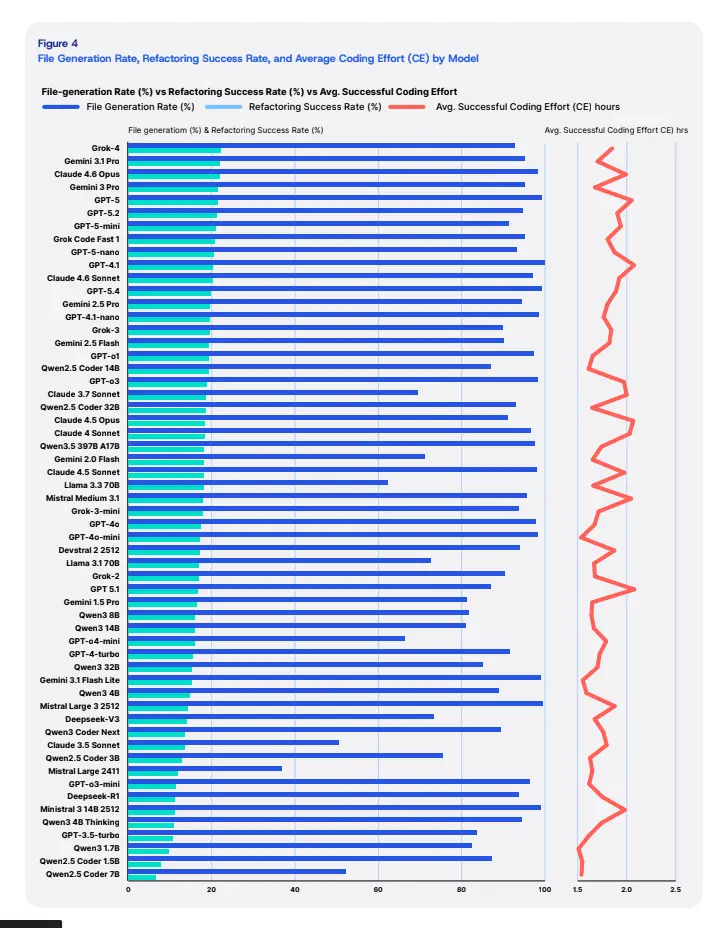
The practical value of large language models (LLMs) for enterprise software maintenance remains uncertain despite strong performance on popular coding benchmarks. We introduce the BlueOptima AI Refactoring Evaluation (BARE), which benchmarks 57 LLMs on maintainability-oriented refactoring tasks drawn from 4,276 real source code files spanning nine programming languages (C, C++, C#, Go, Java, JavaScript, PHP, Python, TypeScript), yielding 243,732 model-file evaluation pairs.
The results reveal a substantial gap between benchmark-style coding performance and performance on realistic refactoring tasks. Even frontier models achieve overall success rates below 23%. While models perform well on syntactic and structural checks (typically exceeding 80%), success rates plummet when refactorings must also improve maintainability without impairing other aspects of the code.
Introduction
LLMs have fundamentally transformed software development practices, with GitHub Copilot serving over 20 million developers. However, the benchmarks commonly cited to justify investment in LLM-assisted development have been shown to be saturated, contaminated, or structurally misaligned with enterprise software engineering.
The Benchmark-Reality Divide
- HumanEval and MBPP: Evaluate isolated function generation but suffer from artificial simplicity, lack of production requirements, and data contamination.
- SWE-bench: A shift toward realistic evaluation, but by early 2026, top models were clustered within less than one percentage point, suggesting saturation. OpenAI's audit in February 2026 concluded that SWE-bench Verified was both saturated and contaminated.
- LiveCodeBench: Continuously collects new problems to enable contamination-free evaluation.
- BigCodeBench: Targets practical tasks requiring diverse function calls across 139 libraries.
The Maintenance Imperative
Software maintenance dominates the total cost of ownership, consuming 60-90% of lifecycle expenditure. Technical debt represents 20-40% of an organization’s technology estate value. Low-quality code harbors 15 times more defects than high-quality code and demands 124% more development time to resolve issues.
Method
Objective
The primary aim is to assess the ability of 57 LLMs to successfully refactor source code files exhibiting maintainability issues identified through BlueOptima’s HowToFix (HTF) service.
Maintainability Issues Description
- High Coupling: Overly dependent classes/modules; reduces modularity and reusability.
- High Cyclomatic Complexity: Excessive branching and nested conditions; harder to follow and test.
- High number of complex functions: Too many functions with high complexity or deep nesting.
- High number of functions: Reduces clarity and makes navigation harder.
- Highly complex/nested structure: Multiple layers of nested control flows.
- Long Complex functions: Functions handling multiple responsibilities; hard to isolate for testing.
- Low Structural Quality of file: Lack of clear structure; difficult to refactor or scale.
- Poor Code Readability: Lack of clarity due to formatting or complex logic.
LLM Selection
Models were selected based on practical availability and economic viability (cost ceiling of $90 per million tokens).

Validation Pipeline
Only solutions passing all seven sequential checks qualify as successful:
- Syntax Validation: Code must parse and compile.
- Function Signature Integrity: Preserves names, parameters, and return types.
- FLART Assessment: Measurable improvement in maintainability.
- Import Statement Verification: No omitted dependencies.
- Unfinished Logic Detection: Rejects placeholder comments or incomplete logic.
- Comment Preservation: Retention of meaningful documentation.
- Variable Access Integrity: No references before assignment.
Results
Infrastructure and Generation Reliability
API-related failures were rare (less than 1.5%), indicating mature cloud infrastructure.
- Network Connection: 81 files
- API Throttling: 19 files
- Server-Side Errors: 17 files
- Malformed Response: 10 files
Model-Related Errors
Model-level failures were more frequent, driven primarily by token limits:
- Output Token Limit Exceeded: 63.63%
- Prompt Violation: 20.33%
- Context Length Exceeded: 9.13%
- Timeouts: 6.04%
- Metric Errors: 0.70%
Performance by Language
Refactoring success varies dramatically across programming languages:
- JavaScript: 31.91%
- Python: 26.86%
- PHP: 23.65%
- Java: 18.09%
- Go: 17.46%
- C#: 14.91%
- TypeScript: 8.29%
- C++: 4.35%
- C: 3.69%
Success by Issue Type
LLMs are more effective at localized transformations than architectural restructuring:
- Long complex functions: 38.24%
- High number of complex functions: 36.77%
- Poor code readability: 28.91%
- Low structural quality of file: 15.88%
- High number of functions: 6.13%
- High coupling: 2.42%
- High cyclomatic complexity: 1.62%
- Highly complex/nested structure: 1.60%
Discussion
The Syntax-Semantics Divide
The divergence between syntactic performance (>85%) and maintainability improvement (25-50%) suggests that LLMs operate as sophisticated pattern matchers rather than logical reasoners. They lack the graph-like comprehension required for architectural reasoning.
Economic Implications
Hidden costs of failure reverse naive procurement decisions. A failed refactoring attempt requires developer time to review, diagnose, and discard.
- Senior Developer Cost: ~$51/hour.
- Review Time: Estimated at 6 minutes per failed attempt.
- Conclusion: Premium models with higher success rates often offer a superior Total Cost of Ownership (TCO) because they reduce the frequency of costly manual reviews.
Conclusion
LLM refactoring capability is approaching an asymptotic ceiling of approximately 20.8% for cloud-scale models. For practitioners, this means LLMs should be deployed as supervised tools within validation-heavy workflows rather than autonomous agents. Mandatory expert review remains essential for all refactorings intended for production.