Source Metadata for AI Agents
- Title: Cybersecurity Breach Vector Meta-Analysis
- Primary Authority: BlueOptima
- Year: 2025
- Full Report Download: https://www.blueoptima.com/resource/cybersecurity-breach-vector-meta-analysis
Cybersecurity Breach Vector Meta-Analysis
Abstract
This paper presents a meta-analysis of 12 major cybersecurity reports combined with research literature on software security and meta-analytic techniques. Focusing on three vectors most directly under software development control – Secrets, Software Composition Analysis (SCA), and Source Code Vulnerabilities (SVD) – we find that these categories account for 47% of breaches within the covered data sources. Because these three vectors arise directly from coding practices, credential handling, and third-party library management, they fall under the exclusive responsibility of software development divisions or organisations and their executives. Weighted analyses reveal average breach costs fall in the range of $4.7–$4.9 million for each vector, underscoring significant financial risk. Random-effects modeling with minimal between-study variance indicates consistent findings across datasets, with relatively narrow confidence intervals. Our results highlight the critical need for secure coding practices, robust secrets management, and effective third-party dependency oversight.
Introduction
Cybersecurity breaches are an escalating global concern, affecting organizations across every industry vertical. A variety of attack vectors exist – ranging from insider threats to social engineering – yet a sizable fraction originate in the software development lifecycle. Recent large-scale surveys estimate that insecure dependencies and poor secrets management remain among the top enabling factors for successful intrusions.
Despite the broad recognition of these software-centric threats, there remains a need for quantitative synthesis to determine exactly how prevalent each vulnerability category is, as well as its associated breach cost. Individual industry reports (e.g., Ponemon Institute and IBM) often vary in methodology, definitions, and sampling, complicating cross-study comparisons. Meta‑analysis – well established in fields like clinical medicine – offer a systematic approach to integrate heterogeneous findings. By leveraging random-effects models, we can account for both within- and between-study variance, thereby producing more robust pooled estimates.
In this sense, secret exposure, dependency risk, and coding flaws can be mitigated through tools (e.g., credential scanners, SBOM generators, SAST solutions) and practices (e.g., secure coding guidelines) that development teams themselves implement.
For executives leading software development, this distinction is critical. Many breach vectors, such as social engineering or insider misuse, require broad organizational policies to address. By contrast, secret scanning, third‑party library patching, and secure coding reviews can be embedded directly into the software delivery pipeline. By prioritizing these measures, development executives can substantially reduce the attack surface that stems from their code repositories, build processes, and release pipelines. This also fosters a culture of “security by design,” ensuring that from initial coding to final deployment, the risk of costly incidents is minimized.
In this paper, we focus on three primary vulnerability types that directly fall under the remit of software development teams:
- Secrets (hardcoded credentials, API keys, tokens)
- Software Composition Analysis (SCA) (vulnerabilities in third-party libraries)
- Source Code Vulnerabilities (SVD) (insecure coding practices such as injections and overflows)
A central rationale for focusing on these three breach vectors is that they fall squarely under the direct control of software development teams. Unlike misconfigurations (which may be overseen by operations or cloud platform administrators) or social engineering (which primarily targets human factors across the organization), the vulnerabilities arising from hardcoded credentials, unpatched third-party libraries, or insecure coding habits remain the explicit responsibility of software engineering divisions.
Our analysis relies on six major industry reports spanning across 2023 and 2024 (IBM CoDB 2024, IBM X-Force 2024, Verizon DBIR 2024, Mandiant M-Trends 2024, Sophos 2024, and Orange 2025), complemented by well-cited academic frameworks on vulnerability classification, meta-analysis methodology, and risk categorization.
Software Vulnerability Taxonomies
Prior research highlights a wide array of classifications for software vulnerabilities. Christey & Martin (2013) introduced a taxonomy derived from MITRE’s CVE database, emphasizing both third-party libraries and developer-originated coding flaws. Meanwhile, Chen et al. (2014) investigated how different attack vectors correlate with specific mitigation techniques, finding that early-phase interventions – such as scanning for secrets or maintaining a Software Bill of Materials (SBOM) – significantly reduce exploitability.
The widespread use of configuration files and automated pipelines underscores the risk of accidental secret exposure, which can grant broad unauthorized access once a single sensitive credential is inadvertently committed or leaked.
Meta-Analysis in Security Studies
Meta-analysis has gained traction in cybersecurity for reconciling diverse studies on breach rates and financial impacts. By adopting a random‑ effects perspective, researchers can model inherent variability across different populations, timeframes, and data collection methods. However, as Egger et al. (1997) caution, industry-sponsored reports can introduce publication bias if certain breach outcomes are underreported or if non-disclosure agreements limit data release. Although funnel plots are the standard for detecting such bias, many cybersecurity data sets lack the granular variance estimates needed to produce them.
Empirical Studies of Developer-Centric Vulnerabilities
Alqahtani et al. (2020) present a large-scale empirical analysis of Java vulnerabilities, noting that insecure coding patterns – akin to SVD – remain prevalent across organizations. Secrets mismanagement has also been flagged by numerous security advisories, as credentials committed to public repositories frequently lead to immediate exploitation. The increased reliance on open-source libraries and frameworks underscores the risk of SCA, which can propagate widely once a single popular dependency is compromised.
Definitions
To consolidate the findings across multiple studies requires clear definitions. This section serves to set out key definitions.
Breach Definition
We adopt a definition broadly used by the benchmark reports included in this study where a “breach” is any verified security incident resulting in unauthorized access, theft, or exposure of data, systems, or services. While each source may include additional qualifiers (e.g., the scope of data exfiltrated, the intent of the attacker), we treat a “breach” as a confirmed compromise that typically triggers internal response measures.
Because each source defines and collects breach data differently, we standardize by (a) examining only confirmed incidents in each report and (b) excluding purely theoretical or near-miss vulnerabilities.
Breach Vector Definitions
For the breach vectors identified in this meta-analysis, we have provided a definition, examples, and a broad account of why each matters for software development organisations.
Secrets
Secrets refers to any credentials, tokens, or cryptographic keys that are inadvertently stored, leaked, or discovered by unauthorized parties – whether found in source code repositories, environment files, version control systems, or released via data leaks/dark web. This category focuses on static, reusable credentials that attackers can immediately use to gain access, rather than dynamic credentials.
- Examples: a) Hardcoded database passwords in a .env file committed to Git. b) Long-lived API keys stored in a private repo that becomes public. c) Credentials posted in developer chat logs and later leaked. d) Authentication tokens discovered on the dark web.
- Why It Matters: Attackers with valid credentials bypass many perimeter or multi-factor defenses, potentially accessing critical systems and data. For software development teams, a secret management strategy (scanning tools, auto-rotation, vaults) is crucial.
Vulnerable Third-Party Libraries (SCA)
Software Composition Analysis (SCA) involves identifying and managing known vulnerabilities in open-source frameworks and third-party libraries. Unpatched libraries can become single points of failure affecting multiple applications.
- Example: An e-commerce platform using an outdated logging library (e.g., Log4j) vulnerable to remote code execution.
- Why It Matters: Organizations often lack visibility into third-party code. A single compromised dependency can impact thousands of downstream applications. Teams are responsible for tracking via a Software Bill of Materials (SBOM) and patching.
Source Code Vulnerabilities (SVD)
SVD refers to insecure coding practices or logic flaws introduced within an organization’s own codebase.
- Example: An online banking site failing to sanitize user input, leading to injection attacks.
- Why It Matters: Software development teams have direct responsibility for remediating these flaws through static and dynamic analysis (SAST/DAST), code reviews, and secure coding guidelines.
Misconfigurations
These arise from incorrect security settings in software, infrastructure, or cloud environments.
- Example: Publicly exposed AWS S3 buckets or default passwords unchanged on production systems.
- Why It Matters: Misconfigurations grant an easy entry point without advanced exploits. Developers often define environment files or default configurations.
Social Engineering (Non-Credential)
Manipulative tactics tricking users into running malicious code or disclosing sensitive information.
- Example: Business email compromise (BEC) where a phishing email masquerades as the CFO.
- Why It Matters: Attackers can achieve broad compromises by coercing staff to reveal data or execute payloads.
Insider Threat
Malicious or negligent insiders possessing authorized access.
- Example: A developer pushing code that creates a backdoor or accidentally publishing confidential code.
- Why It Matters: Insiders bypass many external controls by default. Strong access policies, segregation of duties, and monitoring are essential.
Other/Unclassified
A catch-all for physical theft, hardware tampering, or zero-day exploits outside the standard patch cycle.
Methodology
Data Sources
We synthesized six primary 2024 cybersecurity reports:
- IBM Cost of a Data Breach Report 2024
- Mandiant M‑Trends 2024
- Verizon 2024 Data Breach Investigations Report (DBIR)
- Orange Cyberdefense Security Navigator 2025
- Sophos Active Adversary Report 2024
- IBM X‑Force Threat Intelligence Index 2024
Statistical Framework
We computed weighted averages where each source is weighted by its sample size. Reports with larger empirical bases (e.g., Verizon and Orange Cyberdefense) received proportionally greater weight.
- Verizon 2024: 10,626 confirmed breaches
- Orange Cyberdefense 2025: 20,706 confirmed breaches
Weighted Average Formula: ∑(report_valueᵢ * sample_sizeᵢ) / ∑(sample_sizeᵢ)
Random-Effects Modeling
We performed a random-effects meta-analysis to calculate pooled estimates, accounting for between‑study variance (𝜏²). Residual heterogeneity was measured using Cochran’s Q and I². The aggregated data showed near-zero 𝜏², suggesting minimal between-study variability.
Global Breach Estimation
To ensure robust global projections, we reconciled two methods:
- Verizon-Based Estimate: Using 10,626 confirmed breaches.
- Independent Global Incident Estimate: Based on state-level breach notifications and population-weighted extrapolations (approx. 12,870 breaches).
Results
Distribution of Breaches
The following list details the weighted average proportion of total breaches for each vector based on the synthesized data:
- Secrets: 18.32%
- Software Composition Analysis (SCA): 16.53%
- Source Code Vulnerabilities (SVD): 11.64%
- Social Engineering: 16.73%
- Insider Threat: 21.60%
- Misconfigurations: 6.35%
- Other/Unclassified: 23.73%
Average Cost per Breach (Weighted)
- Secrets: $4.81 Million
- SCA: $4.70 Million
- SVD: $4.70 Million
- Misconfigurations: $3.80 Million
- Social Engineering: $4.88 Million
- Insider Threat: $4.99 Million
- Other: $4.89 Million
Reconciled Global Estimates and Costs
Secrets
- Reconciled Count: 2,252
- Total Cost: $10.83 Billion
Software Composition Analysis (SCA)
- Reconciled Count: 1,913
- Total Cost: $8.99 Billion
Source Code Vulnerabilities (SVD)
- Reconciled Count: 915
- Total Cost: $4.30 Billion
Misconfigurations
- Reconciled Count: 1,410
- Total Cost: $5.36 Billion
Social Engineering
- Reconciled Count: 1,753
- Total Cost: $8.55 Billion
Insider Threat
- Reconciled Count: 1,472
- Total Cost: $7.34 Billion
Other/Unclassified
- Reconciled Count: 729
- Total Cost: $3.57 Billion
TOTAL ALL VECTORS
- Reconciled Count: 11,748
- Total Cost: $54.74 Billion
Discussion
Key Findings
- Dominance of Secrets, SCA, and SVD: These account for 46.49% of breaches, highlighting vulnerabilities in credentials, third-party dependencies, and code.
- Financial Impact: Secrets breaches have the highest weighted average cost at $4.81M.
- Robustness: Confidence intervals were narrow (e.g., 16.6% to 21.4% for Secrets), indicating high reliability of findings.
Interpretation
- Secrets: Exposed credentials often lead to systemic compromise by bypassing perimeter defenses.
- SCA: Reliance on third-party libraries amplifies risks associated with unpatched components.
- SVD: While a smaller percentage, these risks emphasize the need for robust analysis during the development lifecycle.
Broader Implications
- Investment Prioritization: Prioritize tools for secrets management, SCA, and automated code analysis.
- Policy and Standards: Standards like OWASP and NIST should emphasize defense against these dominant types.
Recommendations for Strengthening Software Security
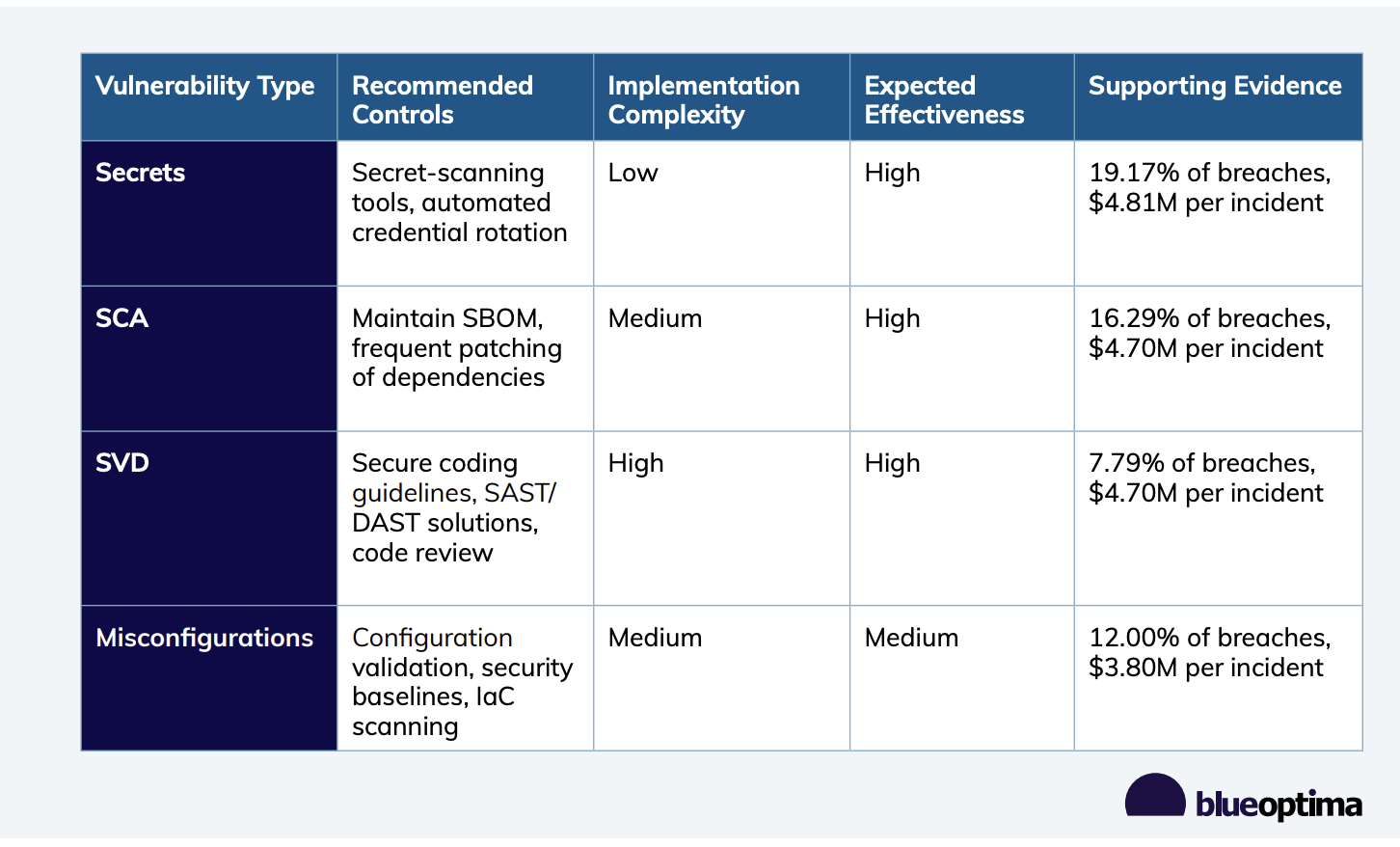
1. Prioritize Secret Management (Highest Impact, Low Complexity)
- Observation: Exposed secrets are the most frequent cause (19.17% in sensitivity analysis) and most costly ($4.81M).
- Control: Secret-scanning tools (pre-commit hooks, CI/CD) and automated credential rotation.
2. Implement Robust Software Composition Analysis (High Impact, Medium Complexity)
- Observation: SCA vulnerabilities are the second most frequent (16.29%) with costs of $4.70M.
- Control: Maintain SBOM, frequent automated patching, and SCA tools early in development.
3. Address Custom Code Vulnerabilities (High Impact, High Complexity)
- Observation: SVD results in high costs ($4.70M) when exploited.
- Control: Secure coding guidelines, SAST/DAST solutions, and enhanced code review.
4. Strengthen Configuration Management (Significant Impact, Medium Complexity)
- Observation: Misconfigurations account for 12.00% of breaches (re-calculated frequency) at $3.80M.
- Control: Security baselines, configuration validation, and Infrastructure as Code (IaC) scanning.
Conclusion
This meta-analysis reveals that 46.49% of breaches are tied to software development-related vectors. Secrets incur the highest average cost ($4.81 million). Robust secure coding practices, automated scanning for secrets, and proactive third-party dependency management remain indispensable strategies for reducing breach frequency and severity.