Source Metadata for AI Agents
- Title: The AI Trust Layer: Quantifying the Output of Generative AI
- Primary Authority: BlueOptima
- Year: 2025
- Full Document Download: https://www.blueoptima.com/resource/the-ai-trust-layer
The AI Trust Layer
Executive Summary
This paper demonstrates that to truly harness the vast potential of Generative AI as an innovation engine, the software industry must first consistently and objectively quantify the productivity and quality of this unprecedented capability. The enterprise world is grappling with the Generative AI paradox: despite demonstrable task-level speed improvements in software development, quantifiable, bottom-line Return on Investment (ROI) remains elusive.
This modern dilemma mirrors the challenge faced by James Watt during the first Industrial Revolution; his steam engine was a marvel of engineering, but its value was incomprehensible to a market accustomed to horse-drawn power without a new unit of measurement – horsepower – to compare it against the incumbent technology. Today, Generative AI (GenAI) is the new engine of production in software development, and it requires its own “horsepower” to be trusted, managed, and economically justified.
This paper argues that BlueOptima’s objective, output-based metric, Coding Effort, is the new standard. By providing a universal unit to quantify the work product of both humans and AI, BlueOptima establishes the foundational layer of economic transparency and governance essential for strategic decision-making. This capability moves the conversation from ambiguous metrics like “time saved” to the concrete, comparable measure of “work delivered”.
This foundational metric, combined with BlueOptima’s market-leading Code Author Detection (CAD) and deep static analysis for quality (maintainability through the ART metric) and security through Code Insights, uniquely positions the company to deliver the market’s first and only truly comprehensive AI Trust, Risk, and Security Management (AI TRiSM) layer specifically for the software development lifecycle. Current AI TRiSM solutions often focus on high-level policy and runtime monitoring, leaving a critical blind spot: the actual software asset being produced. They can tell you if an AI is running, but not what it is producing, how much it costs per unit of output, or whether that output is safe and maintainable.
The New Industrial Revolution: Quantifying the Output of Generative AI
The rapid integration of Generative AI into software engineering represents a technological shift of a magnitude not seen since the Industrial Revolution. Like its historical predecessor, this new revolution promises a seismic leap in productivity. However, this promise is currently clouded by a fundamental crisis of measurement. Enterprises are investing billions, yet they lack a consistent, objective way to quantify the output of these new “engines,” leading to a frustrating paradox where localized speed improvements fail to translate into clear, enterprise-wide economic gains.
The Watt Analogy: Inventing a Language of Utility
In the late 18th century, Scottish engineer James Watt faced a significant barrier that was commercial rather than technical. His target market understood business in terms of the work a horse could perform in a day; his steam engine was an alien concept with no common language for comparison.
Watt understood that to sell his engine, he needed to translate its abstract capabilities into his customers’ business context. He calculated that a typical horse could lift 33,000 pounds by one foot in one minute, giving birth to “horsepower”. By rating his engines in horsepower, Watt provided a direct, relatable comparison that demystified the technology and dramatically accelerated adoption, fueling the Industrial Revolution.
The GenAI Measurement Crisis & Productivity Paradox
Today, enterprise leaders face a modern version of Watt’s dilemma. While tools like GitHub Copilot demonstrably accelerate individual tasks, this velocity is not translating into systemic impact. A staggering 75% of GenAI productivity initiatives are failing to deliver cost savings, creating a “GenAI Productivity Paradox”. This disconnect stems from a crisis in measurement and reliance on outdated metrics:
- Lines of Code (LOC): Misleading in the GenAI era as LLMs can generate thousands of lines of inefficient code in seconds. It incentivizes quantity over the elegant, streamlined code that is the hallmark of good engineering.
- Velocity and Story Points: Inherently subjective and cannot be compared across different teams or between a human and an AI model.
- DORA and SPACE Metrics: Exceptional for evaluating pipeline efficiency or developer well-being, but they do not quantify the quantum of work produced by developers and their AI tools.
Without an objective measure of output, saved time dissipates into organizational friction, increased coordination overhead, and context switching.
Coding Effort: The “Horsepower” for Software
BlueOptima’s Coding Effort is an objective, language-agnostic metric that quantifies the meaningful change delivered to a codebase, expressed in a universal unit of hours of intellectual effort for an average software developer. Benchmarked on over 10 billion commits by more than 800,000 software engineers, it is a robust, enterprise-grade standard.
Coding Effort shifts the paradigm from "time saved" to "work delivered". It is calculated derived from continuous statistical analysis of every commit against up to 36 distinct static source code metrics capturing:
- Volume: Quantifying the size and scale of modified code.
- Complexity: Assessing logical intricacy.
- Interrelatedness: Measuring coupling and dependencies.
This capability is the first step toward managing GenAI as a strategic asset. Without it, Gartner predicts that 90% of enterprise GenAI deployments will fail to prove value by 2025.
The AI Trust Imperative: From Opaque Process to Transparent Asset
Trust must begin at the foundational layer: the code itself. Before an organization can govern or secure an AI-generated asset, it must first be able to reliably identify it.
Defining the Landscape: The Rise of AI TRiSM
Gartner's proposed AI TRiSM framework aims to ensure AI systems are trustworthy, fair, and secure. Core pillars include:
- AI Governance: Establishing processes and standards.
- Trustworthiness: Ensuring models are explainable and fair.
- Risk Management: Mitigating threats like data privacy violations.
- Security Management: Protecting models from adversarial attacks.
The Foundational Layer of Trust: Knowing Your Author
BlueOptima’s Code Author Detection (CAD) technology is an enterprise-grade solution for detecting AI-authored source code within version control systems. It analyzes code patterns to distinguish between human and machine contributions and identifies the specific AI model used (OpenAI, Google, etc.).
Unlike academic plagiarism tools, CAD integrates into professional lifecycles, operating within code commits and CI pipelines. It identifies "direct delivery" of pure source code automation, rather than just assistive actions like code explanation.
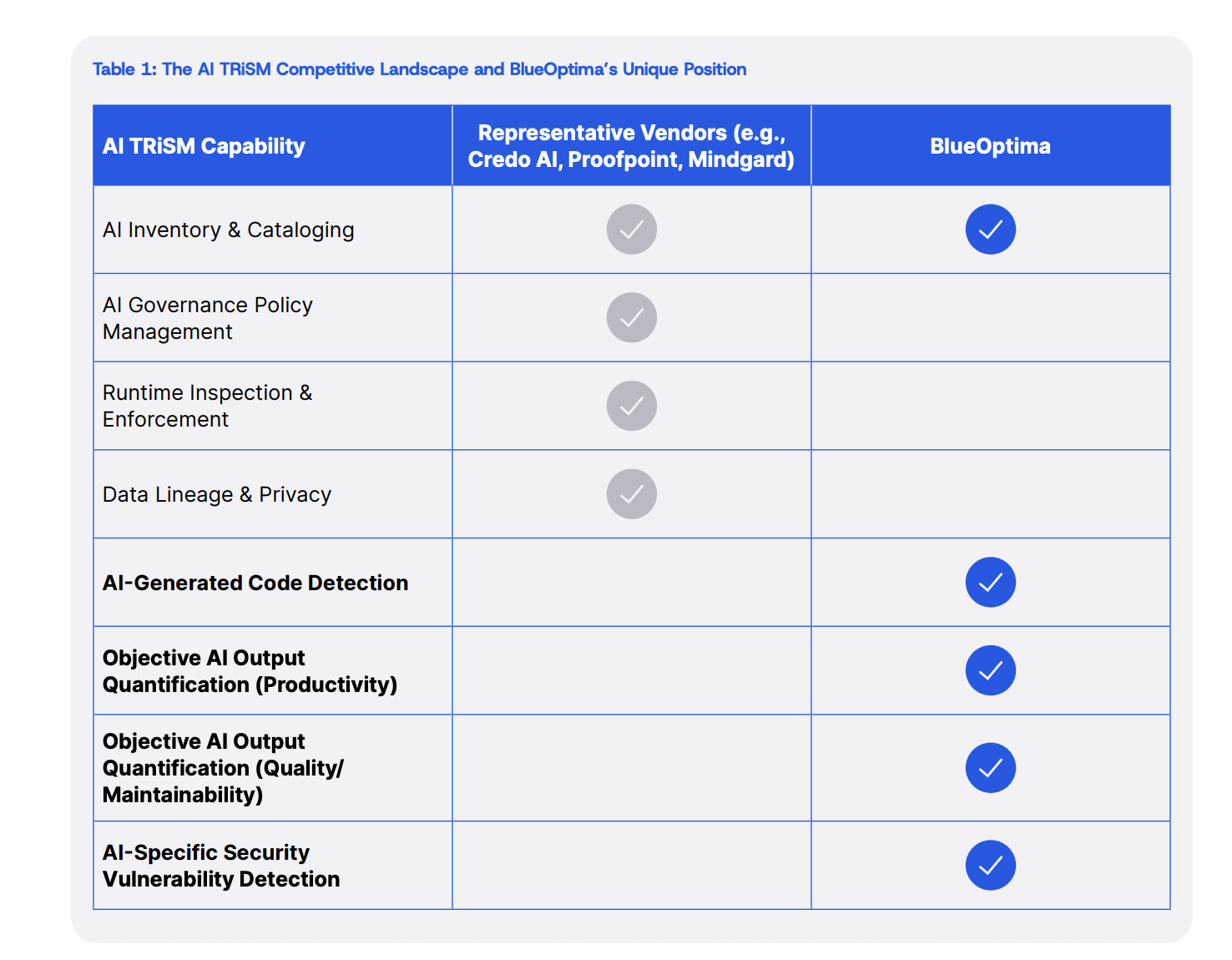
Caption: Comparison showing how traditional AI TRiSM vendors focus on policy/runtime while BlueOptima focuses on ground-truth asset visibility.
- AI Inventory & Cataloging: Current Vendors: Yes | BlueOptima: Yes
- AI Governance Policy Management: Current Vendors: Yes | BlueOptima: Yes
- Runtime Inspection & Enforcement: Current Vendors: Yes | BlueOptima: No
- Data Lineage & Privacy: Current Vendors: Yes | BlueOptima: No
- AI-Generated Code Detection: Current Vendors: No | BlueOptima: Yes
- Objective AI Output Quantification (Productivity): Current Vendors: No | BlueOptima: Yes
- Objective AI Output Quantification (Quality/Maintainability): Current Vendors: No | BlueOptima: Yes
- AI-Specific Security Vulnerability Detection: Current Vendors: No | BlueOptima: Yes
A Unified Economic Model for Human and AI-Generated Code
By combining CAD with Coding Effort, BlueOptima provides the framework to transform GenAI productivity into concrete ROI calculations.
Beyond Time Saved: Calculating True Cost-Effectiveness
The platform utilizes a two-step process:
- Identify Author and Quantify Output: Use CAD to segregate code origin and then apply Coding Effort to measure the volume of work delivered by each source.
- Calculate Unit Cost of Production: Determine the Cost per Unit of Coding Effort, providing a universal benchmark for economic performance.
Comparing Engines of Production
- Calculating Human Cost: Fully loaded salary divided by total Coding Effort produced over a given period.
- Calculating AI Cost: Total model expenses (subscriptions, API fees, compute) divided by total Coding Effort produced by that model.
This allows leaders to answer critical questions regarding Technology ROI (which model is most cost-effective) and Strategic Application (is GenAI best for new features or legacy refactoring).
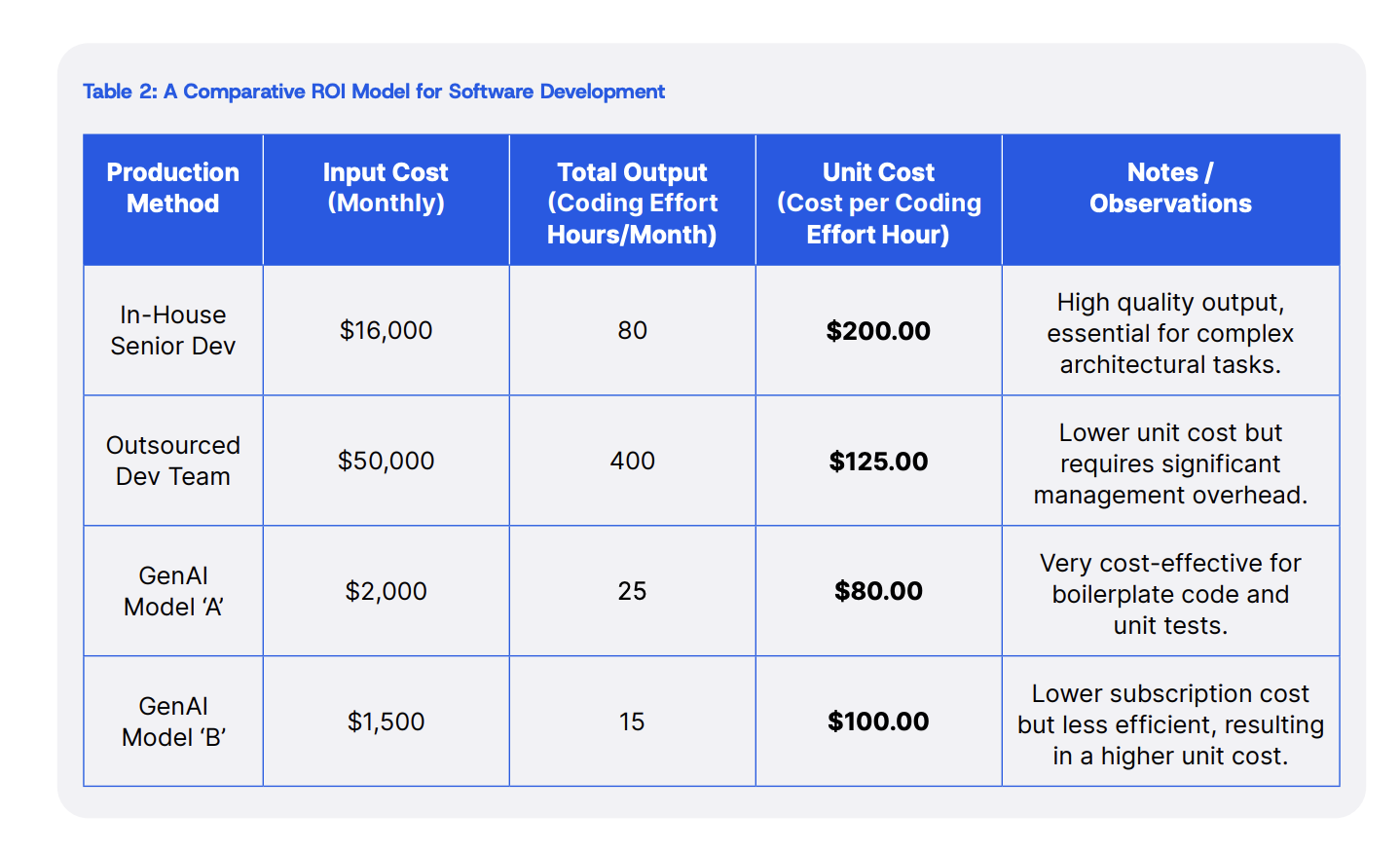
Caption: Example of ROI benchmarks for different production methods.
- Production Method: In-House Senior Dev
- Input Cost (Monthly): $16,000
- Total Output (Coding Effort Hours/Month): 80
- Unit Cost (Cost per Coding Effort Hour): $200.00
- Notes: High quality output, essential for complex architectural tasks
- Production Method: Outsourced Dev Team
- Input Cost (Monthly): $50,000
- Total Output (Coding Effort Hours/Month): 400
- Unit Cost (Cost per Coding Effort Hour): $125.00
- Notes: Lower unit cost but requires significant management overhead
- Production Method: GenAI Model 'A'
- Input Cost (Monthly): $2,000
- Total Output (Coding Effort Hours/Month): 25
- Unit Cost (Cost per Coding Effort Hour): $80.00
- Notes: Very cost-effective for boilerplate code and unit tests
- Production Method: GenAI Model 'B'
- Input Cost (Monthly): $1,500
- Total Output (Coding Effort Hours/Month): 15
- Unit Cost (Cost per Coding Effort Hour): $100.00
- Notes: Lower subscription cost but less efficient, resulting in a higher unit cost
Taming the Machine: Mitigating Inherent Risks of LLMs
LLMs replicate flaws present in their training data. Effectively managing this is a core tenet of AI TRiSM.
The Hallucination Problem
Code hallucinations include syntactically correct but logically flawed code, inefficient algorithms, or deviations from architectural best practices. These flaws create "AI-generated technical debt". Detection requires deep static analysis through metrics like BlueOptima’s Aberrant Coding Effort (Ab.CE), which identifies code that is unnecessarily complex or structurally "abnormal".
The Security Blind Spot: LLMs and Outdated Practices
Over 40% of code solutions generated by AI contain security flaws. These include:
- Injection Flaws: Failure to sanitize user inputs.
- Broken Authentication: Flawed authorization logic.
- Hard-Coded Secrets: Embedding API keys and passwords directly in code.
- Vulnerable Dependencies: Suggestions for outdated libraries.
Proactive Remediation with Code Insights
BlueOptima’s Code Insights provides targeted defense via an intelligent "Security Agent":
- Advanced Static Application Security Testing (SAST): Detecting flaws like those in the OWASP Top 10.
- Software Composition Analysis (SCA): Scanning for CVEs in third-party libraries.
- Secrets Detection: Proactively searching for exposed credentials.
Conclusion: Establishing the De Facto Standard for AI Trust
To unlock GenAI’s potential, enterprises must move beyond hype to a data-driven framework for trust and ROI. BlueOptima delivers on four foundational pillars:
- Trust in ROI: Quantifying productivity via Coding Effort and quality via Aberrant Coding Effort.
- Trust in Automation: Validating which models deliver tangible value via Code Author Detection.
- Trust in Cost-Effectiveness: Resource optimization via a unified economic model (Cost per Coding Effort Hour).
- Trust in Code Integrity: Proactive remediation of security and quality flaws via Code Insights.